오늘은 문자열 데이터를 날짜형으로 바꾼 후 numpy를 활용하여 연산을 하며 데이터 분석을 진행했다. matplotlib 라이브러리를 사용하여 plot, bar, heatmap 형식으로 시각화하고, 더 나아가 folium, markercluster 라이브러리를 사용하여 지도 형식으로 시각화하는 방법에 대해 학습했다.
● 데이터 분석 순서
1) 문제 정의 및 가설 설정하기
2) 데이터 분석 기본 세팅 하기
3) 데이터 분석하기
4) 분석 결과 시각화 하기
5) 최종 결론 내리기
▶ 데이터 기본 세팅하기
import pandas as pd
#import --> pandas 불러와줘
#as pd --> 이제부터 pandas를 pd 라고 부를게
sparta_data = pd.read_table('/content/access_detail.csv', sep=',')
sparta_data.head()● data 이름 지정
● pd.read_table --> pd로 table을 읽어라
● 파일명 우클릭하여 경로 복사
● csv 파일이므로 sep=',' 작성
● head() --> 데이터를 열어서 보여줘라
● 테이블 이름 해석
lecture_id (수강 강의 id)
access_date (접속 시작 날짜 및 시간)
user_id (유저 id)
▶ 데이터 전처리하기
● type 함수를 사용하여 데이터형 확인기
print(type(1))
print(type("hello"))
print(type(sparta_data["access_date"][0]))#type 함수를 이용하여 '정수형'인지 '문자형'인지 확인할 수 있다
#int : 정수형
#str : 문자열
● str형인 access_date 데이터를 fotmat 함수를 사용하여 날짜형으로 바꾸기
format='%Y-%m-%d %H:%M:%S'
sparta_data['access_date_time'] = pd.to_datetime(sparta_data['access_date'], format=format, errors='coerce')
print(type(sparta_data["access_date_time"][0]))
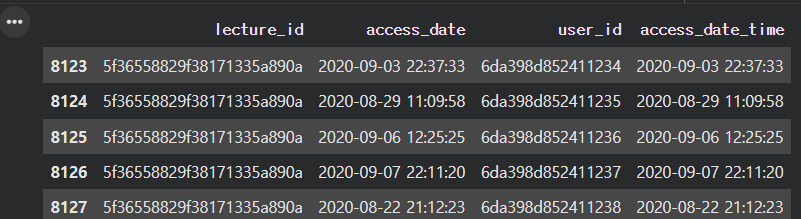
sparta_data.tail(5)● to_datetime --> 괄호 안, 해당 열의 데이터를 날짜와 시간 데이터로 변경 해주는 역할
● <class 'pandas._libs.tslibs.timestamps.Timestamp'> 와 같은 결과가 나온 것을 확인할 수 있다.
즉, 날짜형으로 바뀐 것을 확인할 수 있다.
● 오른쪽 끝에 access_date_time 열이 추가된 것을 확인할 수 있다.- %Y는 년도
- %m은 월
- %d는 일
● 요일 추가하기
sparta_data['access_date_time_weekday'] = sparta_data['access_date_time'].dt.day_name()
sparta_data.tail(5)● [날짜 컬럼].dt.day_name 으로 해당 날짜의 요일을 가져 올수 있다.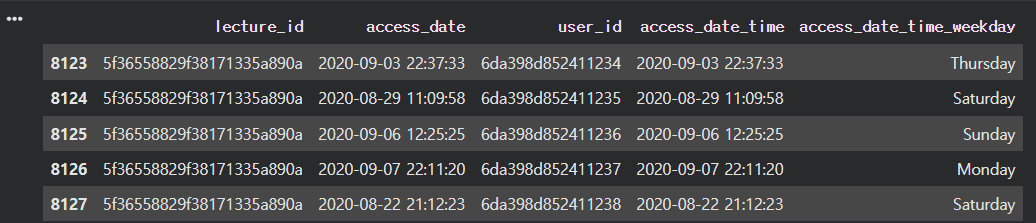
▶ 데이터 분석하기
● groupby, count, agg 변수를 이용하여 요일별 접속한 수강생 수 구하기
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = sparta_data.groupby('access_date_time_weekday')['user_id'].count()
weekdata● groupby(’컬럼명’)를 사용하여 데이터를 특정 기준으로 그룹화한다.
● count()을 이용하여 해당 데이터의 개수를 센다.
● agg(”변수”)를 이용하여 ~~하면 "변수 안 데이터 별 합계"를 구할 수 있다.
☞ 요일 순서대로 정렬 시키기
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = sparta_data.groupby('access_date_time_weekday')['user_id'].count()
weekdata = weekdata.agg(weeks)
weekdata
☞ 시간 별 접속한 수강생 수 전처리 하기
sparta_data['access_date_time_hour'] = sparta_data['access_date_time'].dt.hour
hourdata = sparta_data.groupby('access_date_time_hour')['user_id'].count()
hourdata = hourdata.sort_index()
hourdata[날짜 컬럼].dt.hour 을 사용하여 해당 날짜의 시간 값을 가져오기
sort_index()를 사용하여 해당 데이터를 오름차순(ascending)으로 정렬 하기
반대로, 내림차순(descending)을 하고 싶다면, 'sort_index(ascending=False)'으로 설정 가능
● 지역 분류하기
category_range = set(sparta_data['area'])
print(category_range, len(category_range))● set() 은 데이터의 .중.복.없.이. 각각의 데이터가 unique한 값을 가질 수 있게 한다. 즉, 중복값을 제거할 수 있다.
● len() 은 list에 들어가 있는 원소 개수, 즉 리스트의 크기를 알려주는 함수이다.
● 필요한 데이터만 볼 수 있게 table 가공하기
area_info=sparta_data[['area','latitude','longitude']]
area_info=area_info.drop_duplicates(['area'])
area_info= area_info.reset_index()
area_info = area_info.sort_values(by=["area"], ascending=[True])
area_info● 'area_info' 를 사용하여 원하는 데이터만으로 이루어진 테이블 만들기가 가능하다.
새로운 테이블을 만들 시, 기존의 테이블에서 필요한 "열의 이름"을 대괄호에 넣어 변수에 지정해 준다.
● drop_duplicates()을 이용하여 area 컬럼의 중복 데이터를 처리한다.
● '.reset_index()'를 이용하여 인덱스를 재정렬한다.
● '.sort_values'를 통해 지정 값을 기준으로 레이블을 정렬할 수 있다.
● 'br=["정렬 기준이 될 레이블"]
● 'ascending=[True}' True면 오름차순, False면 내림차순
● 그룹별 수 구하기 + 기존 테이블과 합치기
number_of_students = pd.DataFrame(sparta_data.groupby('area')['user_id'].count())
number_of_students
result = pd.merge(area_info, number_of_students, on="area")
result● 'groupby'를 이용하여 그룹을 설정한다.
● 'count()'를 이용하여 개수를 센다.
● 'merge()'를 이용하여 두 테이블을 병합한다.▶ matplotlib, numpy 사용하여 가장 적절한 고객 관리 타이밍 분석 및 시각화하기
● 요일별 수강생 수 바 그래프 그리기
#그래프 사이즈
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.bar(weekdata.index, weekdata)
#그래프 명
plt.title('요일별 수강 완료 수강생 수')
#그래프 x축 레이블
plt.xlabel('요일')
#그래프 y축 레이블
plt.ylabel('수강생(명)')
#x축 레이블을 90도로 변환
plt.xticks(rotation=90)
#그래프 출력
plt.show()위에 코드를 입력하고 결과를 확인했더니 한글이 보이지 않았다!
↓ ↓ ↓ 한글이 보이지 않을 때 해결 방법 ↓ ↓ ↓
● 한글이 보이지 않을 때 해결 방법!
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf해당 코드를 입력하고 실행한 후, Colab의 런타임>세션 다시 시작을 누른다.
figure 코드 입력 줄 아래에 아래의 코드를 입력한 후 실행한다.
plt.rc('font', family='NanumBarunGothic')한글이 정상적으로 입력된 것을 확인할 수 있다!

→ 수강 완료 수강생 수가 화요일이 가장 많고, 두 번째로 일요일이 가장 많다는 것을 알 수 있다!
● 시간 별 접속 하는 수강생 수의 라인 그래프(꺾은선 그래프) 그리기
#그래프 사이즈 변경
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.plot(hourdata.index, hourdata)
#그래프 명
plt.title('시간별 수강 완료 사용자 수')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('사용자(명)')
#x축 눈금 표시 하기
plt.xticks(np.arange(24))
#그래프 출력
plt.show()np.arange()는 괄호에 명시된 간격으로 배열을 생성 해주는 함수이다.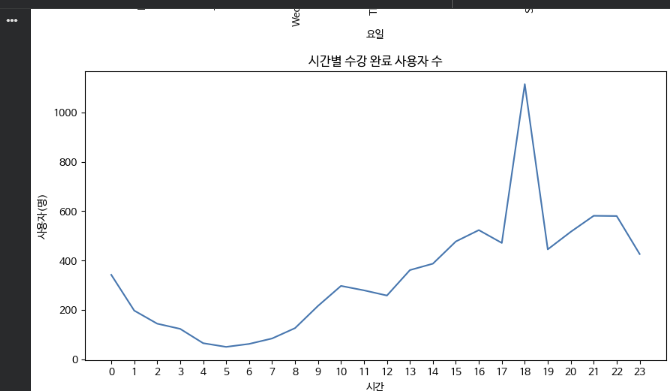
→ 6시에 수강 완료 사용자 수가 가장 많다는 것을 알 수 있다!
● 요일 별 접속 시간 살펴보기 그리고 히트맵으로 나타내기
sparta_data_pivot_table = pd.pivot_table(sparta_data, values='user_id',
index=['access_date_time_weekday'],
columns=['access_date_time_hour'],
aggfunc="count").agg(weeks)
sparta_data_pivot_table
#그래프 사이즈 변경
plt.figure(figsize=(14,5))
#pcolor를 이용하여 heatmap 그리기
plt.pcolor(sparta_data_pivot_table)
#히트맵에서의 x축
plt.xticks(np.arange(0.5, len(sparta_data_pivot_table.columns), 1), sparta_data_pivot_table.columns)
#히트맵에서의 y축
plt.yticks(np.arange(0.5, len(sparta_data_pivot_table.index), 1), sparta_data_pivot_table.index)
#그래프 명
plt.title('요일별 종료 시간 히트맵')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('요일')
#plt.colorbar() 명령어를 추가하면 그래프 옆에 숫자별 색상값을 나타내는 컬러바를 보여 줍니다
plt.colorbar()
plt.show()> 피벗테이블 만들기
● columns : 열에 들어 가는 부분
● index : 행에 들어가는 부분
● aggfunc : 데이터 축약 시 사용할 함수
→ 화요일 6시에 제일 접속량이 많다는 것을 알 수 있다!
● 지도로 시각화하기
import folium
from folium.plugins import MarkerCluster
#대한민국 위도, 경도 설정
m = folium.Map(location=[37.5536067,126.9674308],
zoom_start=11)
m
for n in result.index:
radius = result.loc[n,'user_id']
folium.CircleMarker([result['latitude'][n],result['longitude'][n]],
radius = radius/50, fill=True).add_to(m)
m> 지도 라이브러리
● Folium : 분석한 데이터의 결과를 지도에 그리기 위한 라이브러리
● <arkerCluster : 가까운 거리의 marker들을 군집시켜 해당 건수를 표현해준다.
● loc[n,"열 이름"] => loc[]를 활용하여 n번째의 열을 조회 할수 있다.
즉, n번째의 user의 수를 가져 올 수 있다.
● '.add_to(m)'를 활용하여, 지정해 두었던 우리나라의 지도를 가져올 수 있다.
▶ 실습 하기
● 요일별 수강완료 수강생 수를 구하여 시각화하기
import pandas as pd
qna_data = pd.read_table('/content/done_detail.csv', sep=',')
qna_data.head()
format='%Y-%m-%d %H:%M:%S'
qna_data['done_date_time'] = pd.to_datetime(qna_data['done_date'], format=format, errors='coerce')
print(type(qna_data["done_date_time"][0]))
qna_data['done_date_time_weekday'] = qna_data['done_date_time'].dt.day_name()
qna_data.tail(5)
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = qna_data.groupby('done_date_time_weekday')['user_id'].count()
weekdata = weekdata.agg(weeks)
weekdata
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(10,5))
plt.bar(weekdata.index, weekdata)
plt.title('요일별 수강 완료 수강생 수')
plt.xlabel('요일')
plt.ylabel('수갈생(명)')
plt.xticks(rotation=0)
plt.show()
📅 Day 3. 공정에서 발생할 수 있는 문제 정의하기
1. 공정에서 발생할 수 있는 품질 문제 찾기
| 공정 단계 | 발생할 수 있는 품질 문제 | 원인 가설 | 확인 가능한 데이터 |
| 조립 공정 | PCB 납땜 불량, 회로 단선, 조립 불량, 하우징 체결 불량, LED 불량, 이물 혼입 | 작업자별 조립 편차, 설비 상태 이상, 부품 실장 위치 오차, 리플로우 온도 편차 등 | SMT 온도, AOI 검사 결과, 실장 좌표 데이터, 작업자 작업 이력 |
| 기능 및 안정성 검사 공정 | LED 출력 편차, 과열, 배터리 성능 저하, 충전 불량, 유해물질 기준 초과(RoHS) | 전류.전압 조건 이상, 온도 제어 이상, 부품.케이블 내 유해물질 기준 내 초과 가능 등 | RoHS 검사 데이터, 전류값, 전압값, 온도 데이터, LED 출력 데이터 |
| 후처리 및 외관 공정 | 코팅 불균일, 스크레치, 도장 불량, 이물, 외관 색상 편차 | 코팅 점도 변화, 작업 환경 습도 변화, 설비 오염 등 | 코팅 두께, 습도 데이터, 외관 검사 이미지, 불량 유형 데이터 |
| 포장 공정 | 제품 스크레치, 라벨 오부착, 라벨 오염, 사용 설명서 누락, 포장 스크레치 등 | 작업자 실수, 자동 포장 컨베어 오작동, 라벨 잉크 번짐 등 | 포장 검사 결과, 바코드 데이터, 작업자 작업 이력, 불량 유형 |
- 리플로우 : PCB에 부품을 붙이기 위해 납(솔더)을 녹여 고정하는 공정
- 실장 : PCB 위에 전자부품 배치하고 장착하는 작업
- SMT 온도 : PCB 표면에 전자부품을 부착하는 기술
- AOI : 자동 광학 검사. 카메라와 이미지 분석으로 자동 검사
2. 내가 선택한 핵심 품질 문제 항목작성
| 선택한 공정 | 기능 및 안정성 검사 공정 |
| 정의한 품질 문제 | LED 출력 편차, 과열, 배터리 성능 저하, 충전 불량, 유해물질 기준 초과(RoHS) |
| 이 문제가 중요한 이유 | 홈뷰티 디바이스는 피부에 직접 전기와 열 에너지를 전달하는 제품이기 때문에 출력과 안전성이 기준 범위를 벗어나면 피부 자극, 화상 위험, 제품 효과 저하, 소비자 불만 및 리콜 등의 품질 리스크로 이어질 수 있다. |
| 원인 가설 | 전류 및 전압 조건 이상, 온도 제어 이상, 부품 및 케이블 내 유해물질 기준 내 초과 가능 등 |
| 확인할 수 있는 데이터 | RoHS 검사 데이터, 전류값, 전압값, 온도 데이터, LED 출력 데이터 |
| 데이터를 분석하면 알 수 있는 것 | 특정 공정이나 부품 LOT에서 출력 이상 및 과열 문제가 반복되는지 확인할 수 있으며, 불량 원인을 추적하여 공정 조건 최적화, 부품 교체, 품질 기준 개선 등의 대응이 가능하다. |
3. 문제 정의 문장 만들기
☞ 기능 및 안정성 검사 공정에서 [LED 출력 편차, 과열, 배터리 성능 저하, 충전 불량, 유해물질 기준 초과(RoHS)]문제가 발생할 수 있다. 이 문제는 [RoHS 검사 데이터, 전류값, 전압값, 온도 데이터, LED 출력 데이터]를 분석하면 원인을 파악할 수 있을 것 같다.
오늘은 월요일, 화요일과 다르게 강의를 수강하는데 시간이 좀 걸렸다. 오늘 배운 내용이 바로바로 이해가 되지 않았기도 했고 좀 어렵다고 느껴졌다. 강의를 먼저 듣고 강의자료를 살펴보고 직접 다시 Colab으로 돌려보면서 이해하려고 했다. 그 과정에서 시간이 좀 걸린 것 같다.
그리고 과제를 풀면서 약간 걱정되는 부분이 생겼다. 강사님께서는 '모든 코드를 외우려고 하지 마라.', '코딩을 아무리 잘하는 사람이라도 모든 코드를 외우고 있기는 힘들다'라고 말씀해 주셔서 그나마 좀 다행이다 싶었는데, 그럼 어느 부분까지 알고 있어야 하는지 걱정이 되었다.
계속 고민하다가 내린 결론은 '코드를 내가 읽었을 때 이 코드가 왜, 어떻게 작성되었는지 이해할 수 있는 정도의 수준까지는 되어야 된다'이다. 그래야 내가 데이터를 분석하기 위해 어느 코드를 사용하여 작성할지 결정내릴 수 있고, 완성된 코드를 읽고 잘 못된 부분은 무엇인지 왜 코드가 이렇게 작성되었는지 알 수 있기 때문이다.
'내일배움 본캠프' 카테고리의 다른 글
| [내일배움 본캠프]좋은 가설 세우기와 코호트 분석 (0) | 2026.05.18 |
|---|---|
| [내일배움 본캠프]시각화된 그래프 꾸미기? (0) | 2026.05.15 |
| [내일배움 본캠프]'아티클 스터디'와 '커리어 스터디' 진행 (1) | 2026.05.14 |
| [스파르타 본캠프]Colab으로 데이터 분석하기 (0) | 2026.05.12 |
| [내일배움 본캠프]캠프 시작!(라포형성, 데이터 분석(상관관계분석)) (0) | 2026.05.11 |