☆ To Do List ☆
- AI에이타니
- 통계학 기초 챕터 3, 4 수강
- 머신러닝 기초 1-13까지 수강하기
- 라이브세션(11:00, 19:30)
- 공고 찾아보기
- TIL 작성 및 제출
🤖 에이타니
Q. Python에서 시계열 분해(Time Series Decomposition)를 수행하는 코드, 가법 모델을 사용하여 시계열을 Trend + Seasonality + Residual로 분해하고자 할 때, 빈칸에 들어갈 값은?
from statsmodels.tsa.seasonal import seasonal_decompose
import pandas as pd
# 시계열 데이터 생성
data = pd.Series([100, 120, 130, 110, 105, 125, 135, 115],
index=pd.date_range('2023-01', periods=8, freq='M'))
# 시계열 분해
result = seasonal_decompose(data, model='________', period=4)
→ 시계열 분해 모델에는 가법 모델(additive)과 승법 모델(multiplicative) 두 가지가 있습니다. 가법 모델은 시계열을 Trend + Seasonality + Residual로 분해하며, 계절 변동의 크기가 일정할 때 사용한다. 승법 모델은 Trend × Seasonality × Residual로 분해하며, 계절 변동의 크기가 Trend에 비례할 때 사용한다. 따라서 가법 모델을 사용하려면 'additive'를 입력해야 한다.
📊기초통계
● 6Sigma란?
→ 전사적(품질, 생산 뿐만 아니라 구매, 물류, 마케팅 등) 경영혁신활동
→ 정규분포를 따른다는 가정하에 이루어짐
| σ수준 | 불량률(ppm) | 품질비용(매출액 대비) | 비고 |
| 6σ | 3.4 | 1% | 세계최고 수준 |
| 5σ | 233 | 5 ~ 10% | 우량 수준 |
| 4σ | 6,210 | 10 ~ 15% | 우량 수준 |
| 3σ | 66,807 | 20 ~ 30% | 일반 수준 |
| 2σ | 308,537 | 30 ~ 40% | 일반 수준 |
○ 6Sigma 추진방법
- D(Define) : 과제 선정, 과제 정의, 과제 승인
- M(Measure) : 프로젝트 정의, 현수준 파악, 목표 설정, 잠재 X 도출
- A(Analyze) : 분석 계획, 분석 실시, 핵심 X 도출
- I(Improve) : 사건계획, 아이디어 도출, 개선 최적화, 개선안 실행
- C(Control) : 관리계획 수립, 관리 실행, 승인/확산
● 공정능력이란?
- 공정 혹은 프로세스가 얼마나 균일한 품질의 제품 혹은 서비스를 산출할 수 있는지의 능력
- 공정이 정상적인 관리 상태에 있을 때 그 공정에서 생산되는 제품의 품질 변동이 어느 정도인가를 나타내는 양으로 평가
- σ수준 = % = ppm = Cp
○ 공정능력지수(Cp)
→ 규격의 폭과 공정의 산포를 비교하는 척도
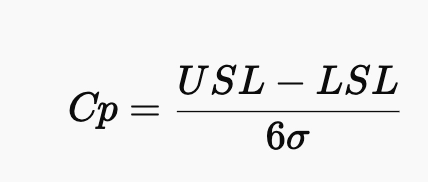
☞ 해석
- Cp가 1.0 미만이면 공정이 지나치게 흔들리며 사양에 맞지 않음
- Cp는 높지만 Cpk가 낮다면? → 공정은 정밀하지만 평균이 한쪽으로 치우침
- Cp ≈ Cpk → 공정 중심이 사양 중앙에 잘 위치함
- Cp 또는 Cpk < 1.0: 불량률 높음
- Cp = 1.33 이상: 적정 수준
- Cp = 2.0 이상: 식스시그마 수준
○ 공정 성능 지수(Cpk)
→ 규격중심과 공정평균이 일치하지 않을 경우 사용

☞ 해석
- Cpk > 1.33 → 안정적이고 중심 정렬된 공정
- Cp > 1.33, Cpk < 1 → 정밀하나 중심이 어긋난 공정
● 측정시스템 분석(MSA;Measurement System Analysis)

→ 데이터의 신뢰성을 확보하기 위해 측정시스템을 평가, 검증하는 과정이 필요하다.
→ 개선 대상 프로세스의 현재 능력을 파악하기 위한 데이터 수집에 앞서, 먼저 데이터가 믿을 수 있는지 확인해야 한다.
- 정확성 : 실제 평균과 측정값의 평균간의 차이를 의미하며, 그 차(bias)가 작을수록 좋다.
- 안정성 : 시간의 변화에 따은 계측결과의 변이
- 선형성 : 측정 범위 전체에 있어 측정 시스템의 일관성
- 반복성 : 한 사람의 측정자가 동일한 측정기로 동일한 대상을 동일한 측정 과정을 사용하여 반복해서 측정할 때 발생하는 산포
- 재현성 : 두 명 이상의 측정자가 동일한 측정기로 동일 대상을 반복해서 측정할 때 발생하는 평균의 차이
○ Gage R&R : 실세 프로세스의 변동을 파악하기 위해 측정 시스템 변동을 먼저 파악하여 공정 중 발생되는 다른 변동과 분리 하고자 하는, 측정시스템 분석 / 재현성과 반복성을 확인하기 위해 사용되는 분석이다.
● 정규화와 표준화의 차이
- 정규화 : 값을 특정 범위로 변환(0 ~ 1)

- 표준화 : 평균과 표준편차를 이용하여 변환(평균 0, 표준편차 1)

● 가설검정 절차

- 귀무가설(H0) : 일반적으로 과거 이론이나 경험적으로 '참'이라고 믿어지는 가설
- 대립가설(H1) : 귀무가설과 다른(혹은 상반된) 입장
- 검정통계량 : 귀무가설을 검정하기(채택 or 기각) 위해 사용되는 통계량
- 유의수준 : 귀무가설이 참일 때 귀무가설을 기각할 확률(α)
- 임곗값 or 기각치 : 귀무가설을 기각할지 기각하지 않을지 기준이 되는 값
- 기각역 : 귀무가설이 기각되는 영역(넓이 α)
● 가설검정 종류
- z-검정 : 모집단의 표준편차를 알고 있고, 표본 수가 충분히 많을 때(n ≥ 30) 사용하는 평균 차이 검정 방법
# 단일표본 z-test
import numpy as np
from scipy.stats import norm
# 샘플 데이터
sample = [50.1, 50.3, 50.2, 50.4, 50.0, 50.5, 50.3, 50.2, 50.1, 50.4,
50.3, 50.2, 50.5, 50.6, 50.2, 50.1, 50.4, 50.3, 50.2, 50.3,
50.2, 50.1, 50.0, 50.4, 50.2, 50.1, 50.3, 50.5, 50.1, 50.3,
50.2, 50.3, 50.4, 50.2, 50.1, 50.0, 50.2, 50.3, 50.4, 50.2]
# 기본 통계
sample_mean = np.mean(sample)
population_mean = 50 # 기준값
population_std = 0.5 # 모집단 표준편차 (알고 있어야 z-test 가능)
n = len(sample)
# Z 검정 통계량 계산
z_stat = (sample_mean - population_mean) / (population_std / np.sqrt(n))
p_value = 2 * (1 - norm.cdf(abs(z_stat))) # 양측 검정
print(f"Z-statistic: {z_stat:.3f}")
print(f"Two-tailed p-value: {p_value:.4f}")
# p-value < 0.05: 차이가 통계적으로 유의미 → 평균이 기준값과 다르다.
# p-value ≥ 0.05: 차이가 우연일 수 있음 → 평균 차이가 유의하지 않다.- t-검정 : 두 집단 간의 평균 차이가 통계적으로 유의미한지 확인하는 검정 방법
# 학생 점수 데이터
scores_method1 = np.random.normal(70, 10, 30)
scores_method2 = np.random.normal(75, 10, 30)
# 독립표본 t검정
t_stat, p_val = stats.ttest_ind(scores_method1, scores_method2)
print(f"T-Statistic: {t_stat}, P-value: {p_val}")- 카이제곱 검정 : 범주형 데이터의 표본 분포가 모집단 분포와 일치하는지 검정(적합도 검정)하거나 두 범주형 변수 간의 독립성을 검정(독립성 검정)
# 적합도 검정
observed = [20, 30, 25, 25]
expected = [25, 25, 25, 25]
chi2_stat, p_value = stats.chisquare(observed, f_exp=expected)
print(f"적합도 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")
# 독립성 검정
observed = np.array([[10, 10, 20], [20, 20, 40]])
chi2_stat, p_value, dof, expected = stats.chi2_contingency(observed)
print(f"독립성 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")
# 성별과 흡연 여부 독립성 검정
observed = np.array([[30, 10], [20, 40]])
chi2_stat, p_value, dof, expected = stats.chi2_contingency(observed)
print(f"독립성 검정 카이제곱 통계량: {chi2_stat}, p-값: {p_value}")


해당 가설검정의 오류는 머신러닝의 성능평가 Confusion Matrix부분과 동일하다고 볼 수 있다.
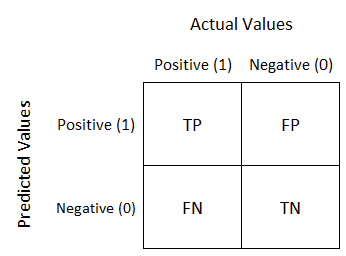
- 제 1종 오류(α) = FN : 실제로는 귀무가설이 옳은데 검정 결과 귀무가설을 기각하는 오류
- 제 2종 오류(β) = FP : 실제로는 귀무가설이 틀렸는데 검정 결과 귀무가설이 옳은 것으로 판단하는 오류
→ 1-α, 1-β를 크게 할수록 옳은 결정을 할 가능성이 높아진다. But α와 β의 크기는 서로 반대 방향으로 변하고 있으므로, 1-α와 1-β를 동시에 크게 하기에는 현실적으로 불가능하다.
→ 가설의 채택여부가 실제로 미치는 영향을 감안해서 더 중요하다고 판단되는 가설채택에 따른 오류의 확률을 미리 지정된 값 이하로 하여 주는 검정방법을 찾는게 현실적이다.
→ 제 2종 오류의 가능성을 최소화하는 것이 가장 현실적이면서 좋은 통계적 검정법이다.
→ 연구자의 입장에서 보면 귀무가설이 거부되어야할 때 1-β가 커지도록 하는 것이 바람직하며, 1-β를 검정력 이라고 부른다.
▶ 가설검증 파이썬 코드
# 기존 약물(A)와 새로운 약물(B) 효과 데이터 생성
A = np.random.normal(50, 10, 100)
B = np.random.normal(55, 10, 100)
# 평균 효과 계산
mean_A = np.mean(A)
mean_B = np.mean(B)
# t-검정 수행
t_stat, p_value = stats.ttest_ind(A, B)
print(f"A 평균 효과: {mean_A}")
print(f"B 평균 효과: {mean_B}")
print(f"t-검정 통계량: {t_stat}")
print(f"p-값: {p_value}")
# t-검정의 p-값 확인 (위 예시에서 계산된 p-값 사용)
print(f"p-값: {p_value}")
if p_value < 0.05:
print("귀무가설을 기각합니다. 통계적으로 유의미한 차이가 있습니다.")
else:
print("귀무가설을 기각하지 않습니다. 통계적으로 유의미한 차이가 없습니다.")'내일배움 본캠프' 카테고리의 다른 글
| [내일배움 본캠프] 통계에서 재현성의 중요성 (0) | 2026.06.23 |
|---|---|
| [내일배움 본캠프] 통계를 이용한 데이터 분석 (1) | 2026.06.22 |
| [내일배움 본캠프] 기술통계 (0) | 2026.06.18 |
| [내일배움 본캠프] 기초통계와 머신러닝 (0) | 2026.06.17 |
| [내일배움 본캠프] 커리어데이 (0) | 2026.06.16 |